TRL turns a raw pre-trained LLM into an aligned reasoning agent
TRL (Transformers Reinforcement Learning) is Hugging Face's production-grade library for every stage of post-training: from supervised fine-tuning through offline preference optimisation and highly scalable online GRPO. Every trainer is a thin subclass of transformers.Trainer — familiar API, production performance.
Three stages transform a raw pre-trained LLM into an aligned reasoning agent
Every frontier assistant model goes through this pipeline. TRL covers all three stages with production-grade trainers. The key insight: alignment is not a single step — it is a staged progression from imitation (SFT) to preference learning (DPO/reward model) to reinforcement optimisation (GRPO/PPO).
Infographic 2 — The modern alignment pipeline (redrawn)
Infographic 10 — Framework relationship: breadth vs depth
§ 03
GRPO deep dive
Group Relative Policy Optimisation
GRPO eliminates the value model from PPO — cutting VRAM by roughly 25–50%
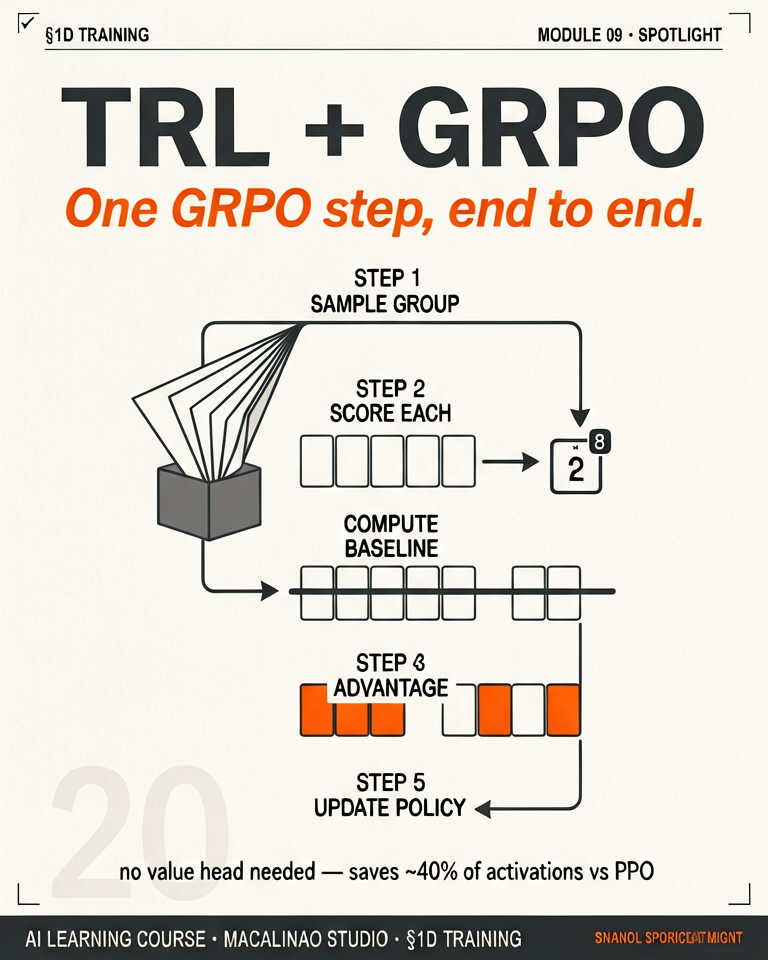
GRPO generates a group of completions for each prompt, scores them with a verifier, then uses the group's own average reward as the baseline — no separate value model needed. Removing the critic saves roughly 25–50% VRAM; the "up to 90%" figures you see come from Unsloth's whole-stack optimisation on top of GRPO, not from the algorithm itself. GRPO variants (DAPO, Dr. GRPO, GSPO) now ship in mainstream trainers, and vLLM-backed rollouts inside GRPOTrainer are what make online RL tractable — at lab scale, verl and OpenRLHF are the heavy-duty alternatives.
Infographic 6 — GRPO: the AI reasoning engine — 5 steps
Infographic 5 — RLVR & patience is all you need
The Concept
If the probability of the correct answer is > 0, an untrained model called infinitely will eventually guess correctly ("Patience is All You Need"). RL accelerates this by actively learning from bad signals (0s) to prune the output distribution away from wrong answers.
§ 04
PPO vs GRPO
PPO vs GRPO
PPO is the heavyweight predecessor — GRPO is the lightweight successor
Both are on-policy RL algorithms that keep the model close to a reference policy via KL regularisation. The critical difference: PPO needs a separate value model to estimate future rewards. GRPO eliminates this by using group statistics as the baseline instead.
Infographic 7/9 — PPO architecture vs GRPO architecture
VRAM comparison — 8B model, 20K context window
PPO — what the value model does
The value model V(s) predicts total future reward from each token position. This lets PPO compute accurate advantage estimates at every step. Training the value model alongside the policy doubles VRAM usage and adds instability — it must be trained at the same time as the policy it is trying to evaluate.
GRPO — why group statistics work
Instead of predicting future reward, GRPO observes multiple complete trajectories for the same prompt. The group average reward is a Monte Carlo estimate of expected reward — simpler, more direct, and needing no separate network. TRL's default is num_generations=8; DeepSeekMath used 64. More samples = more stable advantage estimates.
§ 05
Reward design
Designing reward functions & verifiers
The secret to robust GRPO is a rubric — not a single reward
The biggest practical lesson from training reasoning models: a single "correct/incorrect" reward is too sparse. The model gets no signal until it reaches the final answer. A rubric — a stack of smaller verifiable rewards — gives the model richer feedback at every step and leads to dramatically more stable training.
From dual A100s to a single 8 GB consumer GPU — same model, same task
Unsloth patches TRL's GRPOTrainer kernels to avoid materialising massive logit tensors, implements Standby Mode KV-Cache (releasing vLLM's KV cache during training to reclaim memory), and uses ultra-long context optimisations (dynamic flattened sequence chunking + offloading log-softmax activations). The result: 90% VRAM reduction on 8B models.
Infographic 8/9 — TRL + Unsloth efficiency stack
Desktop-level training — what this enables
Before Unsloth, GRPO training an 8B reasoning model required institutional compute. After Unsloth: a researcher with an RTX 3070 can fine-tune an 8B model with GRPO on math or coding tasks. This democratises reasoning model training the same way QLoRA democratised SFT in 2023. In ~100 training steps on a single consumer GPU you can observe real GRPO gains — the model adopting the reasoning format and improving on the verifier — but R1-class capability takes far more compute.