A neural codec (EnCodec, SoundStream) compresses audio into discrete tokens at ~75 tokens/second. A transformer then predicts those tokens from text + a speaker reference — exactly the next-token loop from module 11, pointed at sound. Decoding the predicted tokens reconstructs the waveform.
CLONING
3 seconds of reference is enough to condition a voice
A speaker encoder distills a short clip into an embedding; generation conditions on it. That's why cloning got cheap — the model isn't trained per-voice, it is prompted per-voice. Quality scales with reference length: 3s captures timbre, 30s captures cadence and habits.
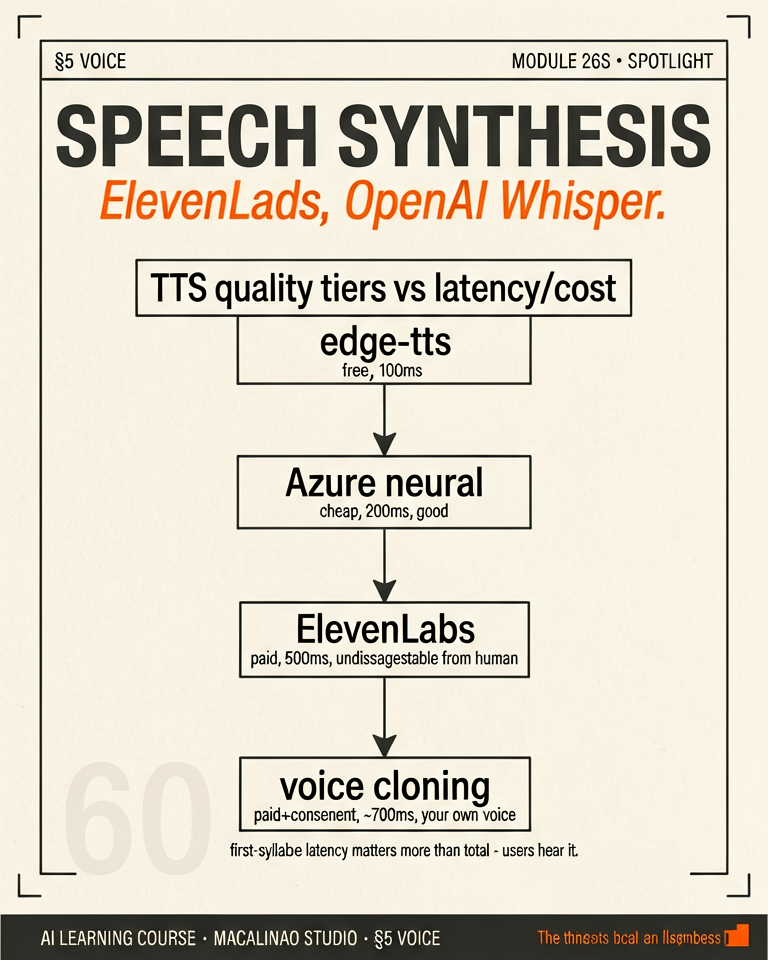
THE TIERS
Latency and naturalness define the market
Free/fast: edge-tts (used for this course's 125 narrations) — instant, slightly robotic. Mid: ElevenLabs, XTTS — natural, ~1–5s. Frontier: streaming codec LMs (ElevenLabs Flash, Cartesia Sonic) at sub-100ms time-to-first-sound for live agents. Pick by use case: batch narration tolerates latency; a phone attendant cannot.
ETHICS
Consent, watermarking, refusal
Voice is identity. Responsible pipelines verify consent for cloned voices, watermark generated audio, and refuse public-figure cloning. The technical bar to misuse is now near zero — the guardrails have to live in process and policy.
§ 02
The lesson
The platforms turning text into natural speech — and speech back into text.
SPEECH STACK
TTS leaders and the STT inverse
ElevenLabs leads commercial TTS, but the field is crowded: OpenAI, Cartesia, Google, and MiniMax compete on the API side, and a strong open-weight field (Kokoro, F5-TTS, CosyVoice, Chatterbox) closes the gap from below. ElevenLabs' architecture is unpublished — treat any description of its internals as speculation. OpenAI Whisper is the inverse problem (speech→text), included here for contrast: multilingual STT across 99 languages, famous for robustness to accents and noise — and equally famous for hallucinating text on silence or music. Speech-to-speech models (GPT-realtime-class, Gemini Live) are the post-cascade paradigm: one model listens and speaks with no text pipeline in the middle.