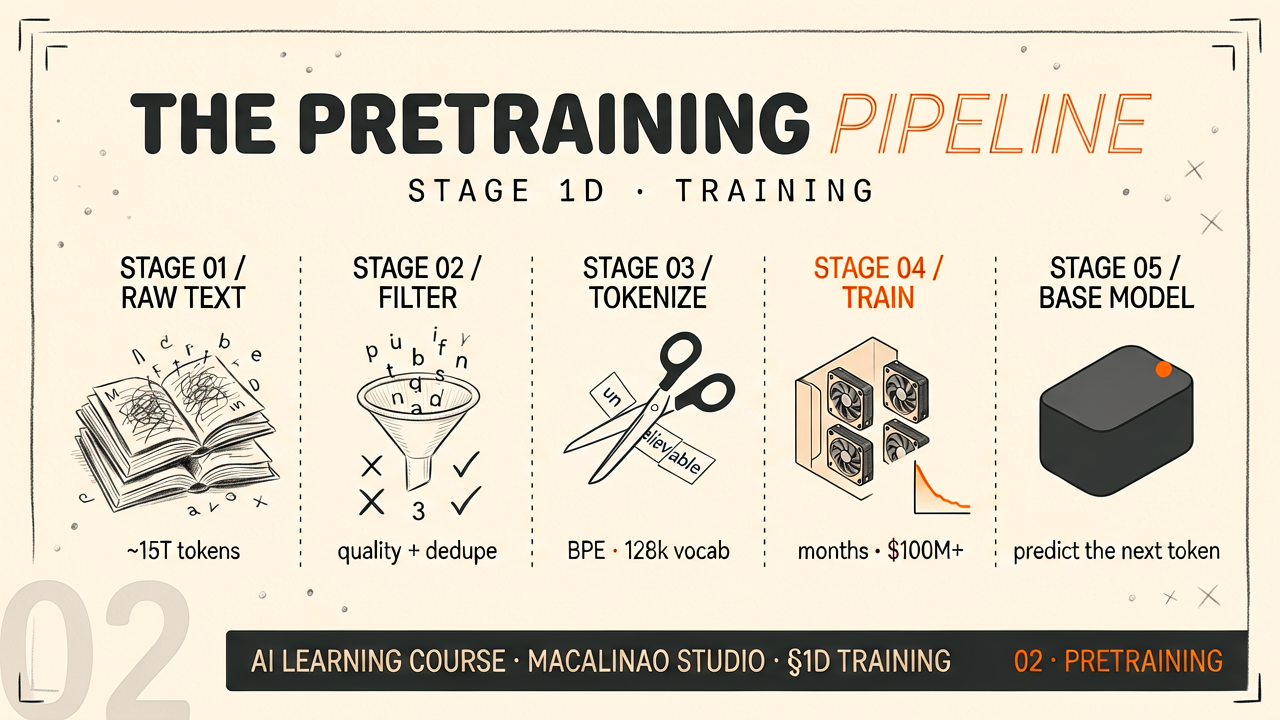
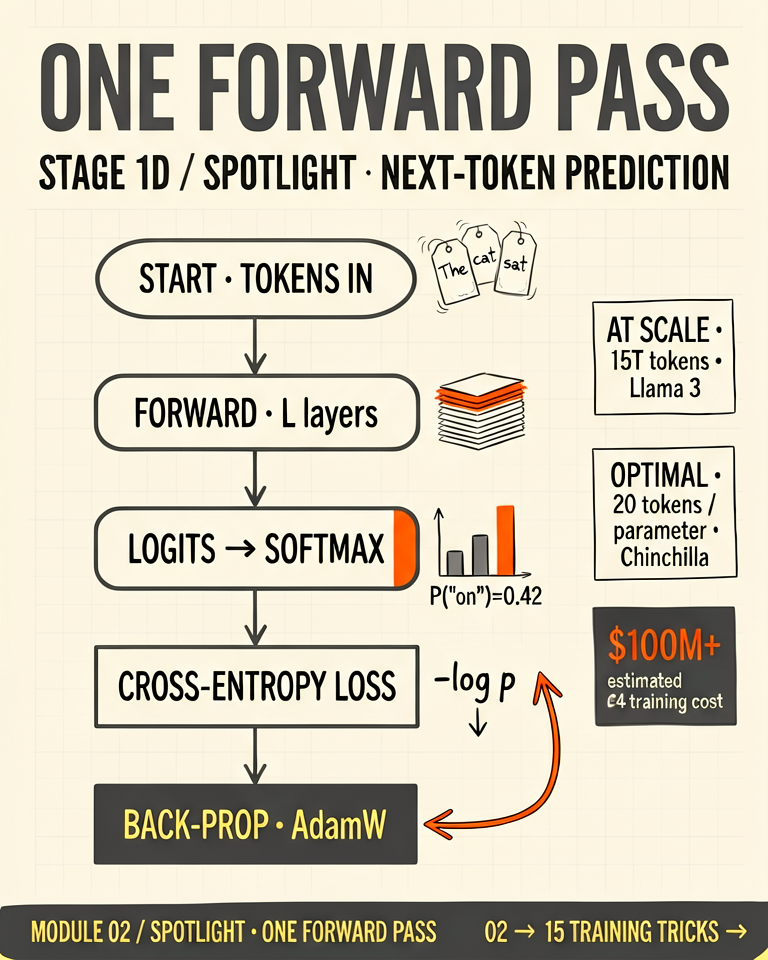
Dataset formatsWhat instruction data looks like
Data comes as (prompt, completion) pairs. Common formats: Alpaca (instruction + input + output fields), ShareGPT (multi-turn conversations), ChatML (system + user + assistant turns). Quality matters far more than quantity — 1,000 carefully curated examples often outperform 100,000 noisy ones.
Train on completions onlyDon't compute loss on the prompt
Compute the cross-entropy loss ONLY on the assistant's response tokens, not on the user's prompt. This teaches the model to generate good answers rather than to reproduce questions. The QLoRA paper showed this significantly improves accuracy for multi-turn conversations. In Unsloth: train_on_responses_only.
Full fine-tuning vs LoRA vs QLoRAThe three SFT strategies — memory comparison for a 7B model
Full fine-tuning updates all weights — highest quality but risks catastrophic forgetting and requires enormous compute. LoRA freezes base weights and trains only small adapter matrices (~1% of params). QLoRA further quantizes the frozen base to 4-bit NF4, fitting a 70B model in roughly 40–48 GB — a single 48 GB GPU.
Instruction tuningFewer examples, better generalization
Instruction tuning uses (prompt, completion) pairs that demonstrate behaviour — not task-specific answers. Models learn to generalize the behaviour pattern. InstructGPT showed a 1.3B model — instruction-tuned and then RLHF-trained, not SFT alone — outperformed a raw 175B GPT-3 on helpfulness ratings from human evaluators.
Catastrophic forgettingThe danger of full fine-tuning
When all weights are updated during SFT, the model can "forget" general abilities learned during pretraining. Fine-tuning a coding model might make it lose conversational ability. PEFT methods (LoRA, adapters) mitigate this by keeping base weights frozen and only training small additions.