The "Mountain Climber" AnalogyHow does an AI actually "learn"?
Imagine you are blindfolded on a foggy mountain, and your goal is to find the lowest valley (which represents 0 mistakes).
You feel the slope with your feet and take a step downhill. But what if you take a step that is too big? You might jump over the valley and land higher up on the opposite cliff! What if your step is too small? It will take you a million years to get to the bottom. Sometimes there are small "fake" valleys (local minimums) that trap you before you reach the true bottom.
Interactive: Tune the AdamW Optimizer
Use the controls to launch a mathematical "ball" down the loss curve.
Learning Rate: How big of a step the ball takes. (Default ~3e-4)
Momentum (β₁): Allows the ball to roll up small bumps to escape fake valleys! (Default ~0.9)
RMSProp (β₂) & Weight Decay (λ): (Hidden for simple physics) Defaults are usually β₂=0.95, λ=0.1.
Why Momentum mattersEscaping Local Minima
If you look at the graph above, there is a small dip on the left side before the massive dip on the right. Without momentum, a ball dropped on the left side would roll into the small dip and stop.
With Momentum (standard in the AdamW Optimizer), the ball builds up speed as it rolls, giving it enough juice to roll out of the small dip and find the true lowest point.
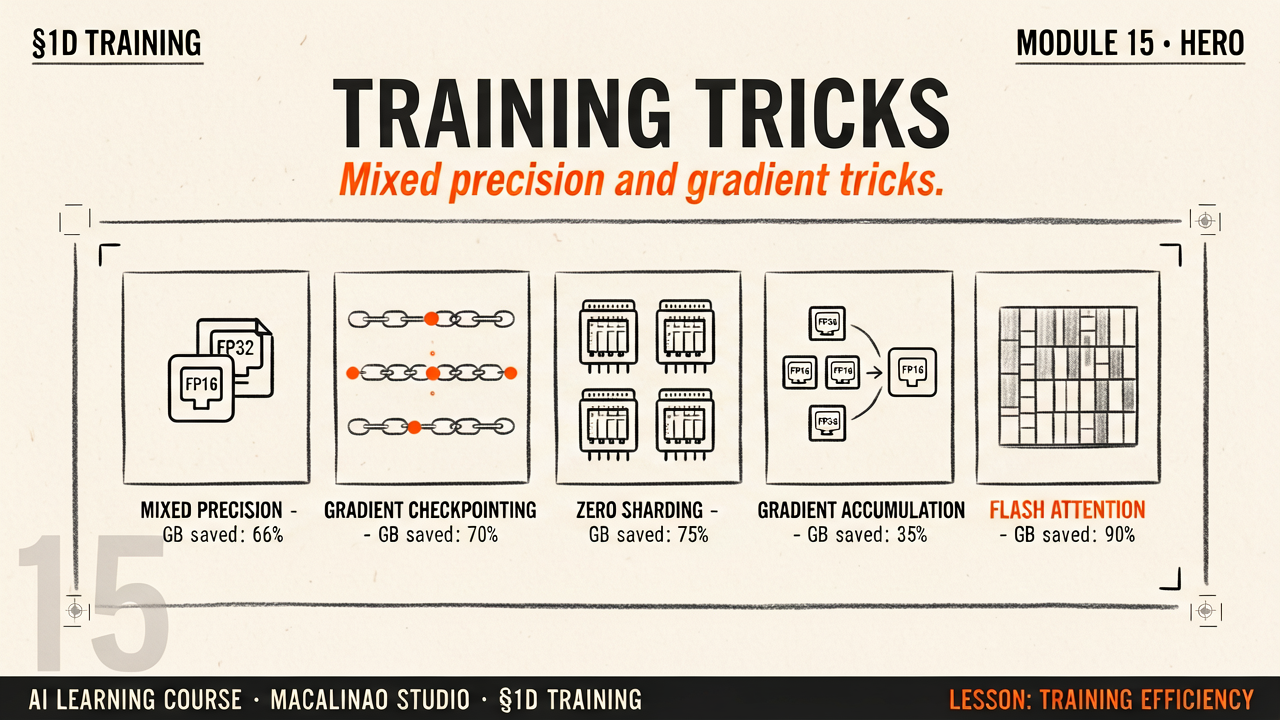
Backpack SplittingMixed Precision & ZeRO
Even if you have the perfect optimizer, carrying all the math requires heavy "backpacks" (memory).
Mixed Precision (BF16): Instead of calculating math with about 7 significant decimal digits (FP32), the AI uses just 2–3 (BF16) to save weight, while keeping the big numbers accurate.
ZeRO: Instead of one computer carrying the whole backpack, a cluster of 8 Graphics Cards dynamically toss the items to each other so nobody gets crushed.
Since DeepSeek-V3, frontier labs go even lighter: FP8 training (with BF16 master weights) is standard at frontier scale, and Muon became the first credible challenger to the AdamW optimizer — used at trillion-parameter scale in 2025.
The everyday workhorsesFour tricks every real training run uses
Gradient accumulation: Your GPU can only fit a tiny batch? Add up the gradients from several small batches before taking a step — it behaves like one big batch.
Gradient checkpointing: Instead of storing every intermediate result, throw most of them away and recompute them during the backward pass — trading a little time for a lot of VRAM.
FlashAttention: Computes exact attention with fused GPU kernels that never write the giant attention matrix to memory — faster and lighter, no approximation.
Learning-rate schedules: Start with a gentle warmup, then decay (cosine or warmup-stable-decay) so the ball takes big steps early and tiny careful steps near the valley floor.