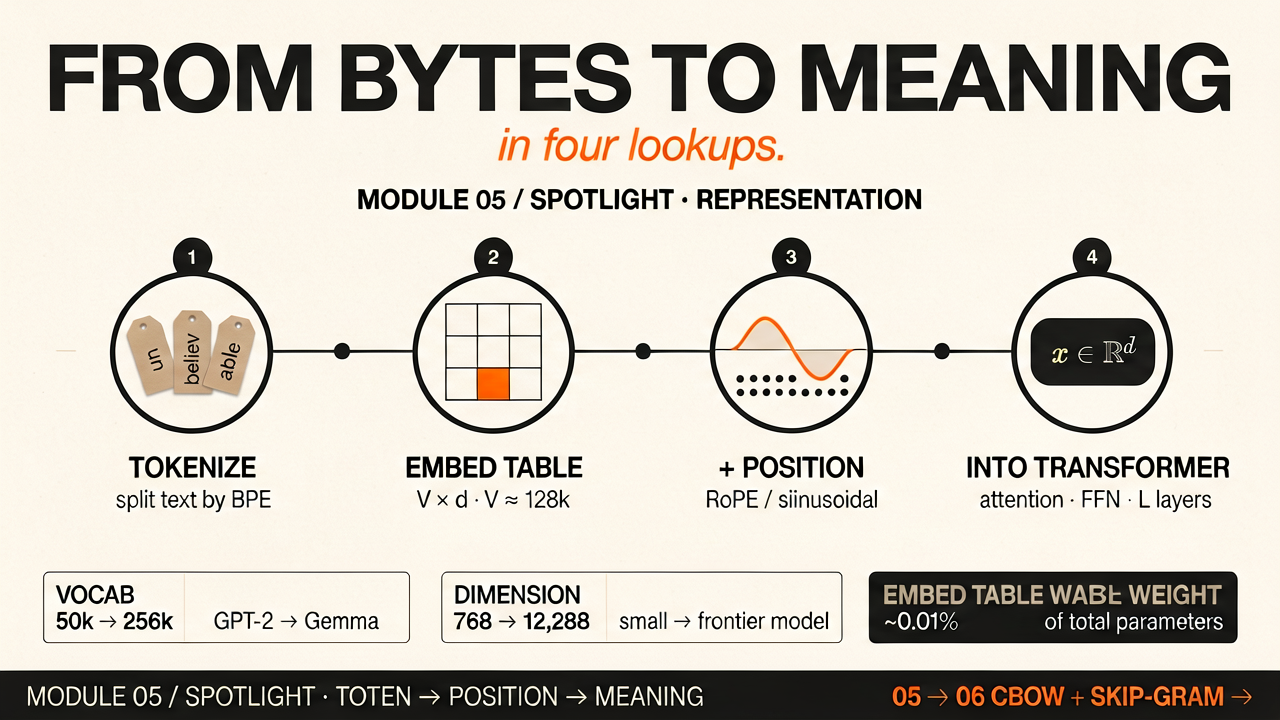
Every word becomes a number — but some words become many numbers
BPE (Byte-Pair Encoding) merges the most frequent pairs of bytes until the vocabulary is full. Common English words become single tokens. Rare words, technical terms, and non-English text get split into multiple tokens. This directly affects how much the model "costs" to process each piece of text — and why LLMs sometimes struggle with certain languages and tasks. Click each token below to see how many bytes it uses.
Why byte count matters for LLMs
Cost at inference You pay per token, not per character. "neurotransmitter" (16 chars) costs 4 tokens in GPT-4. A Chinese document 3× longer than an English one might cost the same number of tokens — or more. Why arithmetic is hard In GPT-2/Llama-2-era tokenizers, numbers were often split digit-by-digit: "1234" → ["1","2","3","4"] = 4 tokens, forcing the model to learn that 4 separate tokens represent one number. That behaviour is now historical — modern tokenizers group digits in threes, so "1234" → ["123","4"] = 2 tokens, which makes arithmetic noticeably easier.
Vocabulary sizes across models
GPT-2 and GPT-3: 50,257 tokens (the same GPT-2 tokenizer) · GPT-3.5/GPT-4 (cl100k): ~100,000 tokens · Llama 3: 128,256 tokens · GPT-4o-era models (o200k): ~200,000 tokens · Gemma: 256,000 tokens. The trend is clearly toward larger vocabularies: more common words get single-token treatment — fewer splits, lower cost, but a bigger embedding table.
The BPE algorithm
Start with individual bytes (256 possible). Count all adjacent byte pairs in a large corpus. Merge the most frequent pair into a new token. Repeat until vocabulary is full. Running this on English text produces tokens that roughly correspond to common words and word-pieces.
§ 02
2 — Positional encoding
Layer 1 — positional embedding
Transformers are order-blind — positional encoding gives them a sense of position
A transformer's self-attention mechanism treats all tokens the same regardless of position — it is permutation-invariant. "The cat sat" and "sat cat the" would produce identical attention scores without positional information. Positional encoding solves this by adding a position-dependent signal to each token's embedding before it enters the transformer.
Why position matters
"The dog bit the man" and "The man bit the dog" contain the same words but have completely different meanings. Without positional encoding, a transformer would compute identical representations for both sentences. Position tells the model which word is the subject, which is the verb, which is the object.
The evolution
Sinusoidal (hardcoded, generalises to unseen lengths) → Learned absolute (trained, ceiling at max length seen during training) → Relative (T5, encodes distance between tokens) → ALiBi (linear bias, no explicit encoding) → RoPE (rotates Q&K vectors, dominant standard since 2022) → YaRN (extends RoPE to 500K+ context).
§ 03
3 — Semantic word map
Layer 1 — the geometry of meaning
Similar words cluster together in high-dimensional embedding space
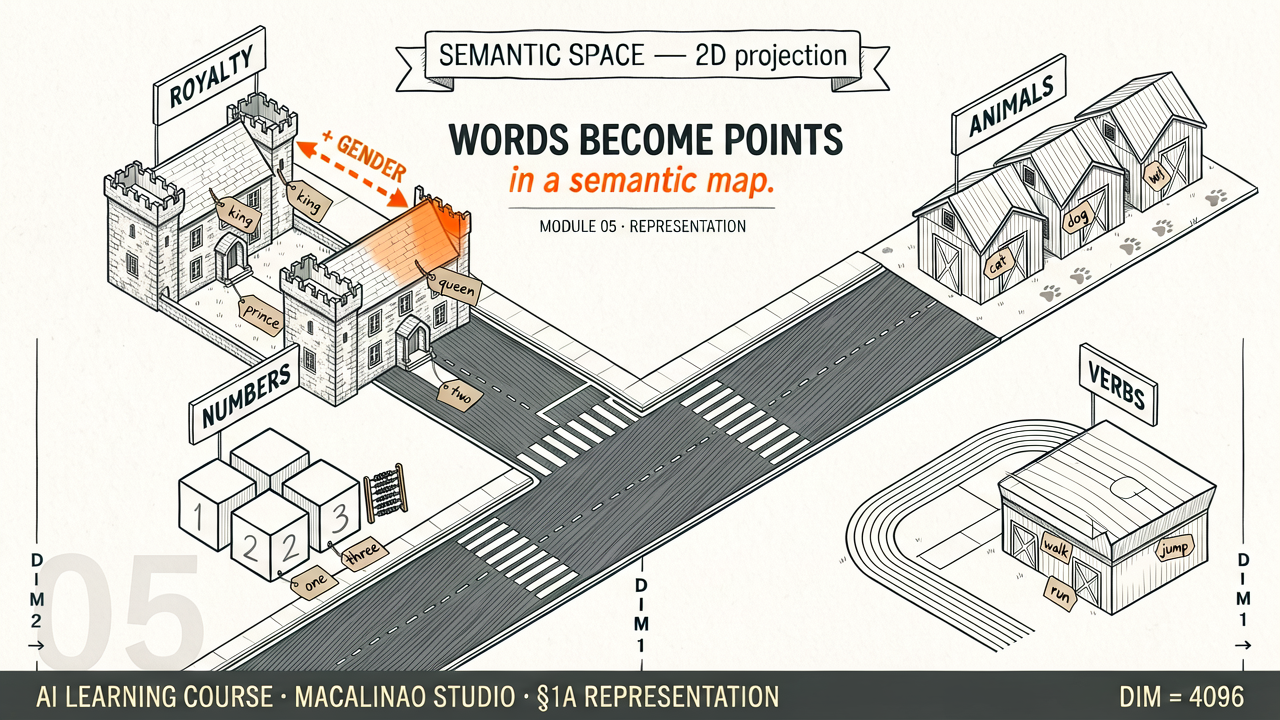
Each word is represented as a point in a space with hundreds or thousands of dimensions. Words with similar meanings end up near each other. Relationships become directions: the direction from "man" to "woman" is the same as the direction from "king" to "queen". The 2D map below is a simplified projection of these high-dimensional clusters — hover over any word to see its semantic group.
Vector arithmetic
Meaning encodes as direction and distance
The famous equation: king − man + woman ≈ queen. This works because the direction from "man" to "woman" (the gender direction) is consistent across related word pairs. The same direction works for: actor→actress, he→she, his→her. The distance between words encodes semantic similarity: "cat" and "kitten" are close; "cat" and "democracy" are far apart.
Context reshapes meaning
The same word, different vectors
Static embeddings (Word2Vec) assign one fixed vector per word — "bank" always has the same representation. Contextual embeddings (BERT, GPT) produce different vectors for the same word depending on context. "river bank" and "savings bank" produce completely different embedding vectors for "bank" — capturing true word sense disambiguation.
§ 04
4 — Scale comparison
From Word2Vec to GPT-4 — 11 years of scaling
How embedding dimensions, parameters, training data, and cost changed at each generation
The transformer revolution was not just architectural — it was a massive scaling of every dimension simultaneously. Parameters grew from millions to trillions, training data from billions of words to trillions of tokens, and embedding dimensions from 100 to 12,288. The bars below show relative scale across four representative models.
The naive view is that d dimensions hold d concepts — one per axis. The reality is stranger and better: in high dimensions, exponentially many directions can be nearly orthogonal to each other, so a model can pack far more features than dimensions into the same space, with each feature stored as a direction that barely interferes with the others. Anthropic's interpretability work calls this superposition — models represent many more concepts than they have dimensions by accepting a little interference between them. Bigger d means more room: less interference, finer distinctions, more precise disambiguation.
Diminishing returns
Scaling is not free. Doubling embedding dimensions roughly quadruples the weight-matrix memory and compute (the projection matrices are O(d²)), while activation memory doubles. The field is now exploring sparse attention, mixture-of-experts, and quantization to continue improving quality without proportional compute costs.
Two things the word "embedding" means today
Weight tying, and the embedding models inside RAG
Two clarifications worth carrying forward. First, weight tying: in most language models the input embedding table is shared with the output head — the same matrix that turns tokens into vectors is reused (transposed) to turn the final hidden state back into vocabulary logits. One table, two jobs, a large parameter saving. Second, when a RAG pipeline talks about its "embedding model" (the model that vectorises documents for retrieval), that is a full transformer encoder producing contextual sentence-level vectors — not Word2Vec. Static word vectors and modern embedding models share a name and a goal, but not an architecture.
§ 05
The playground.
Theory above, instrument below. This interactive panel runs live in the page — drag, type, and watch the mechanism respond.