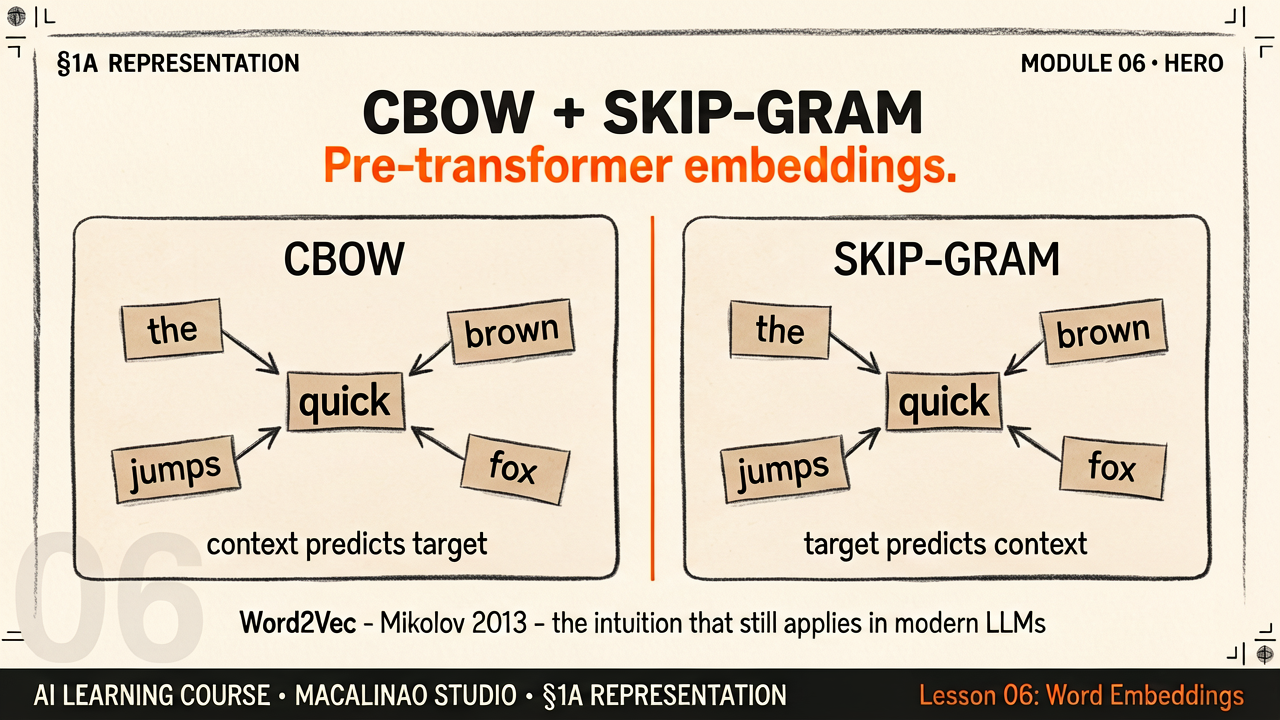
Many → One: use the surrounding words to predict the missing word
CBOW takes a window of context words around a gap and predicts what word belongs in the gap. The "bag" in the name means the order of context words doesn't matter — only their average embedding does. Training millions of these predictions forces the model to learn that similar words appear in similar contexts, which is exactly what makes embeddings useful.
How training works
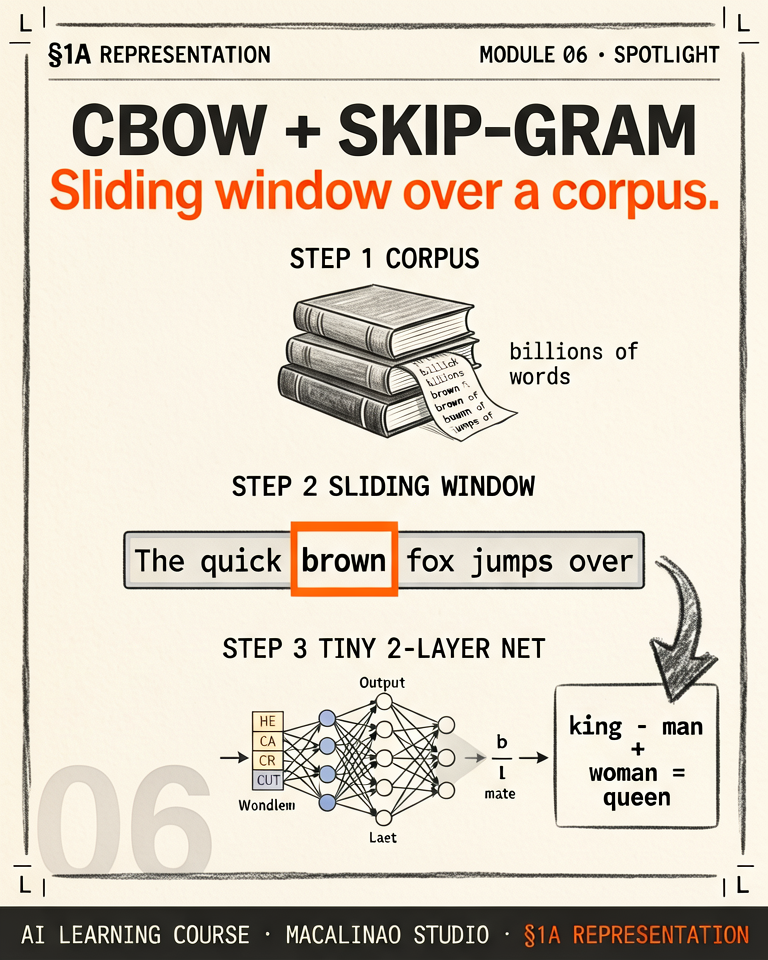
For each position in the corpus, the algorithm slides a window over the text. Word2vec's default is window=5, meaning up to 5 context words on each side of the target (the effective width is randomly sampled per example, which weights nearby words more). The context words are embedded, averaged together, and passed through a two-layer network. The output is a probability over all vocabulary words. Loss = cross-entropy between predicted distribution and the actual target word.
Connection to BERT
BERT's Masked Language Modelling (MLM) is CBOW scaled up. Instead of a small sliding context window, BERT uses the full sentence. Instead of averaging embeddings, BERT uses deep transformer attention. Instead of a shallow network, BERT uses 12–24 transformer layers. Same idea, massively more powerful execution.
§ 02
Skip-gram
Skip-gram
One → Many: use one word to predict all its surrounding context words
Skip-gram inverts CBOW: given one input word, predict each context word in the surrounding window. For a window of ±2, each input word generates 4 training examples. This means rare words get many more training signals than in CBOW, making Skip-gram much better at learning embeddings for rare or technical vocabulary.
Negative sampling — the key speedup
Why training on all 50,000 words per step is impractical — and how to fix it
Without negative sampling, every training step requires computing a softmax over the entire vocabulary (50,000+ items) — enormously slow. Negative sampling instead updates weights for just the correct context word (positive) plus 5–20 randomly chosen wrong words (negatives). The model learns to distinguish real context from random noise. This makes training ~1,000× faster with minimal quality loss.
§ 03
Side-by-side
CBOW vs Skip-gram — when to use each
Two algorithms, different strengths
Both CBOW and Skip-gram learn the same kind of embedding — dense vectors where similar words end up nearby. But they differ in speed, quality for rare words, and what they are optimised for. In practice, Skip-gram with negative sampling tends to produce better embeddings for most tasks, especially when rare words matter.
What they share
Both use a two-layer neural network with no hidden-layer activation function. Both learn two embedding matrices: one for input words, one for output words. Both are trained with stochastic gradient descent. But they are not interchangeable in quality: CBOW trains faster, while skip-gram tends to produce better embeddings for rare words and for most downstream tasks.
Window size tradeoff
Smaller window (±1–2): embeddings capture syntactic relationships — words that appear in similar grammatical positions become similar. Larger window (±5–10): embeddings capture semantic/topical relationships — words used in similar topic contexts become similar. Most Word2Vec implementations default to ±5.
§ 04
Family tree
The embedding algorithm family tree — 1986 to 2024
Every major word representation method and how they connect
The history of word embeddings is a story of increasing expressiveness: from manually crafted features, to static vectors, to context-dependent representations, to the trillion-parameter transformers that are now the embedding layer of every frontier LLM.
Then
Word2Vec, CBOW, and skip-gram (2013–2017) trained one static vector per word — the dominant way to represent meaning before transformers.
Now · June 2026
Historical for LLM work — you will never train Word2Vec in production. But the predictive and contrastive intuition survives in every 2026 embedding model, and negative sampling lives on as contrastive learning in CLIP and sentence-embedding models.
§ 05
The playground.
Theory above, instrument below. This interactive panel runs live in the page — drag, type, and watch the mechanism respond.