The model landscape (snapshot: early 2025)Key models from each architecture family — click a card to explore
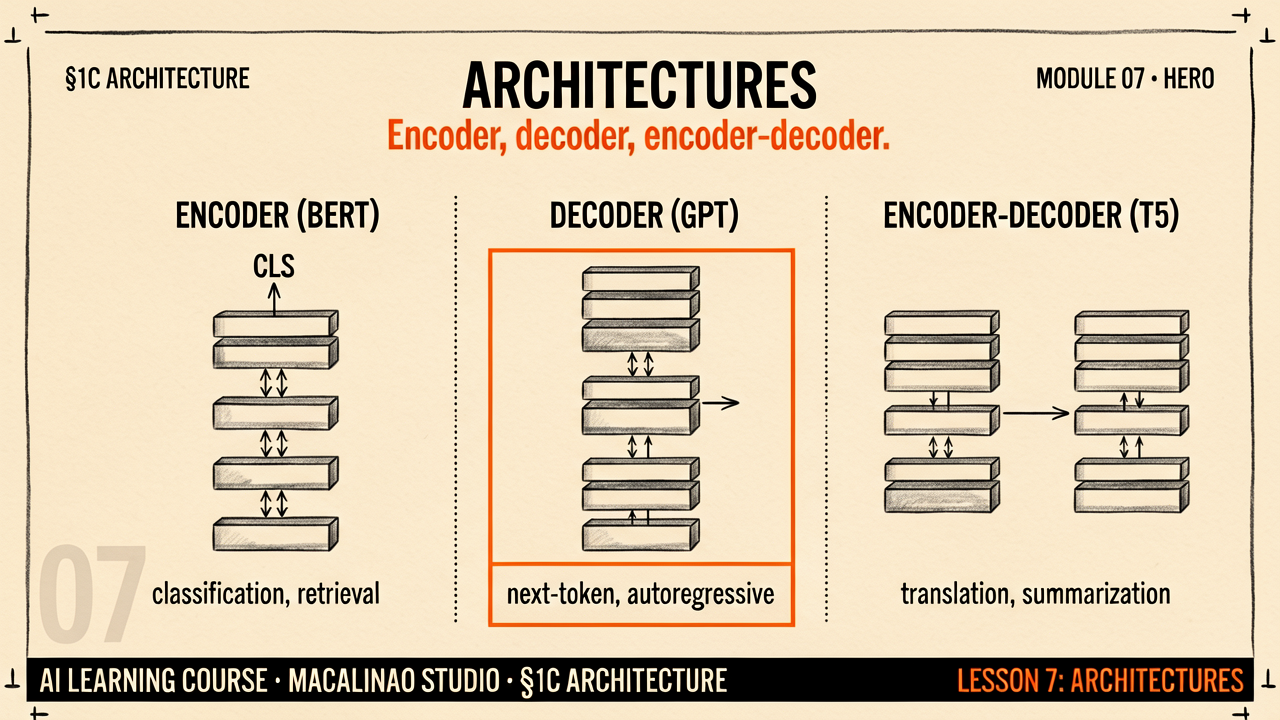
Every model below is a transformer at heart — the differences are in which components they use, what data they trained on, and what objectives they optimised for.
BERT Google 2018 110M MLM bidirectional
RoBERTa Meta 2019 125M improved BERT no NSP
DeBERTa v3 Microsoft 2021 86M disentangled SOTA NLU
ModernBERT Answer.AI + LightOn 2024 8K context RoPE 2T tokens
T5 Google 2019 60M–11B text-to-text relative pos
BART Meta 2019 400M denoising summarisation
FLAN-T5 Google 2022 instruction tuned 1800+ tasks
Whisper OpenAI 2022 39M–1.55B speech 99 languages
GPT-3 OpenAI 2020 175B few-shot closed
GPT-4o OpenAI 2024 multimodal omni closed
Llama 3.3 Meta 2024 70B open weights RoPE
Claude 3.7 Anthropic 2025 reasoning 200K ctx closed
Gemini 2.5 Google 2025 multimodal 1M ctx closed
Mistral 7B Mistral AI 2023 7B SWA open
DeepSeek-R1 DeepSeek 2025 reasoning GRPO open
Qwen 2.5 Alibaba 2024 0.5B–72B multilingual open
Gemma 3 Google 2025 1B–27B consumer HW open