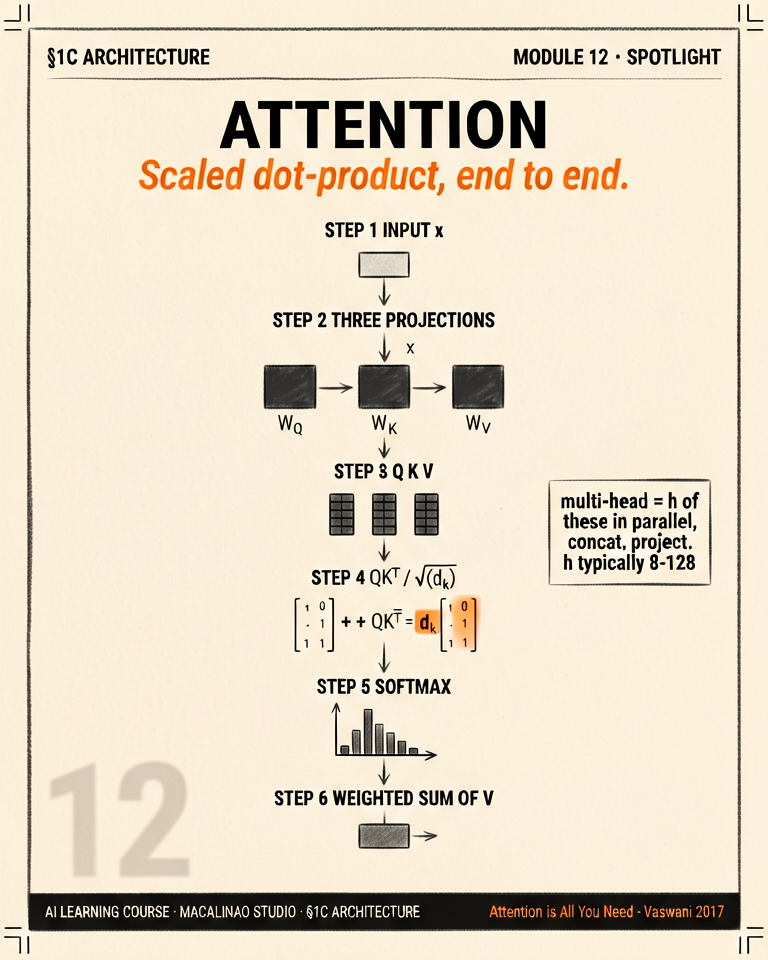
For every token, attention computes how relevant every other token is (softmax(QKᵀ/√d)) and blends their values by that relevance. That single operation — run in parallel across heads and layers — is how transformers move information between positions.
WHY √d
The scaling factor keeps softmax in its useful zone
Dot products of high-dimensional vectors grow with dimension; unscaled, the softmax saturates into a one-hot and gradients die. Dividing by √d_k keeps scores in the range where softmax stays soft and trainable. Tiny detail, load-bearing.
CAUSAL MASK
The mask is what makes it a language model
During training every position predicts its next token simultaneously — the causal mask (an upper-triangular −∞) guarantees position t can only see positions ≤ t. One matrix turns a parallel batch computation into an honest autoregressive model.
§ 02
The lesson
The magic that lets AI "read" context like a human
The "Highlight Reel" Analogy
How do you solve a mystery? You connect the clues.
Think about reading a mystery novel. When you read the word "bank", how do you know if it's a river bank or a money bank? You don't look at the word in isolation—you scan the surrounding sentences for clues. If you see the words "water" or "fishing" nearby, you mentally highlight those words to give "bank" its meaning.
This is exactly how an AI's Attention Mechanism works. When the AI processes a sentence, it doesn't just read left-to-right. Every single word acts like a detective, looking at every other word in the text and assigning an "attention score" to decide which words are the most important clues.
Interactive: Be the Detective
Hover over any word below to see what it "pays attention to". Thicker, brighter lines mean a higher Attention Score. Notice how context words heavily influence the main subjects!
Queries, Keys, and Values
The Three Questions
Under the hood, every word asks and answers three things:
1. Query (What am I looking for?) The word "bank" says: "I need a clue to tell me what kind of bank I am."
2. Key (What do I contain?) The word "river" says: "I am related to water and nature."
3. Value (What is my actual meaning?) Every Query is compared against every Key, and softmax turns those scores into weights — so "bank" absorbs a weighted blend of all the Values, dominated by the best matches like "river". Now, "bank" mathematically contains the concept of water!
Why it changed the world
Parallel Reading
Attention was actually invented in 2014 (Bahdanau et al.) as an add-on that helped RNN translation models look back at the input. The 2017 Google paper Attention Is All You Need made the radical move: throw away the RNN entirely and keep only attention. Before that, the RNNs doing the reading processed text one word at a time, like a cassette tape.
A pure-attention model looks at everything all at once. Word 1 looks at Word 100 on the exact same step that Word 100 looks at Word 1. This parallel processing is the secret behind why modern LLMs can be trained so quickly on millions of books using giant graphics cards (GPUs).
§ 03
The playground.
Theory above, instrument below. This interactive panel runs live in the page — drag, type, and watch the mechanism respond.