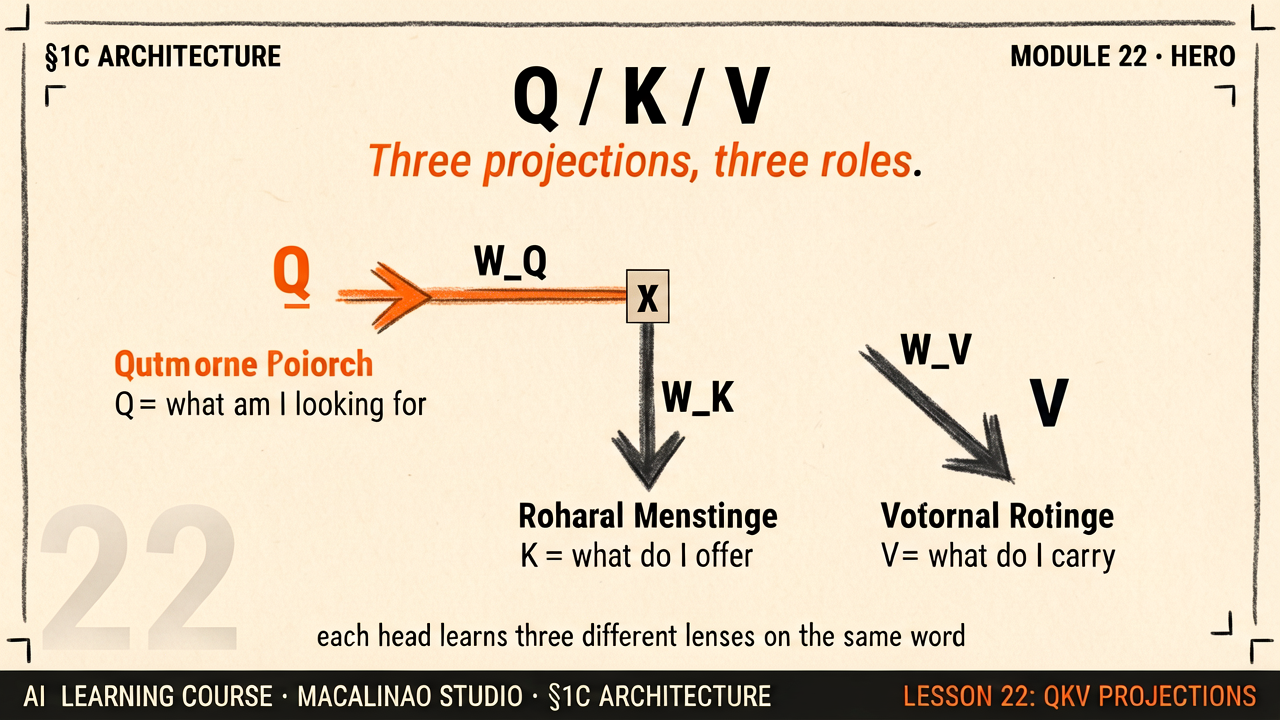
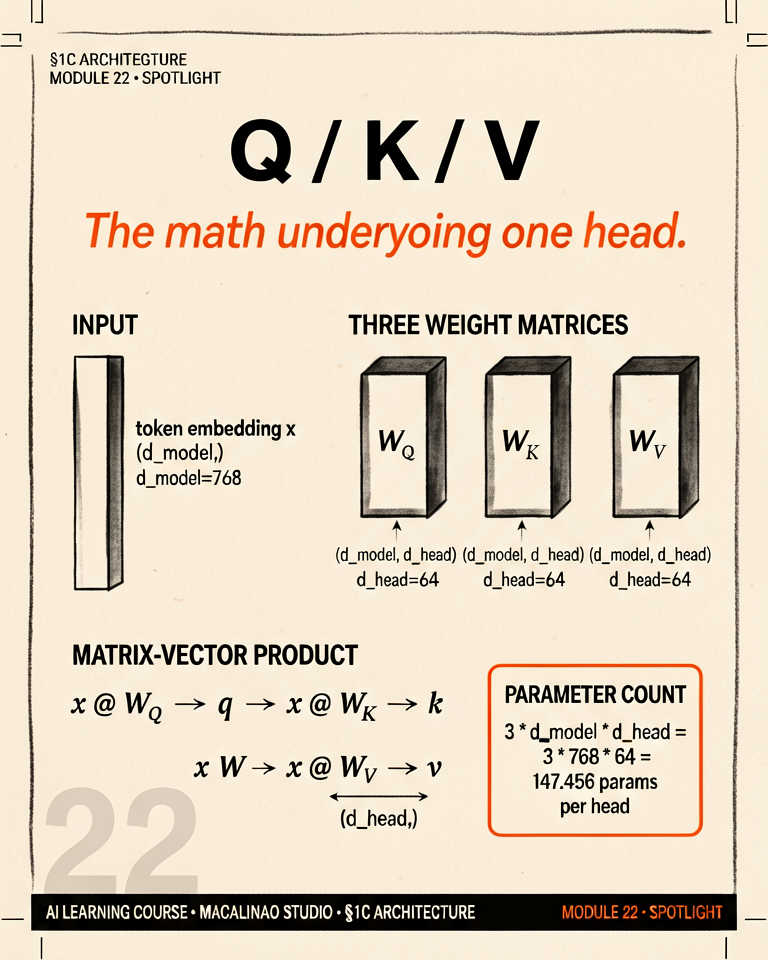
Each token's embedding x is multiplied by three trained matrices: Q = xW_q, K = xW_k, V = xW_v. The same token wears three hats: Query — what am I looking for? Key — what can others find me by? Value — what content do I hand over if someone attends to me?
INTUITION
A library lookup, vectorized
Think of a card catalog: your query is the topic you walk in with, each book's key is its index card, and the value is the book's contents. Attention scores are Q·Kᵀ — how well your request matches each card — and the output is a weighted blend of the matching books' contents. Example: the query from "it" in "the cat drank because it was thirsty" lands hardest on the key of "cat", so cat's value flows into it's new representation.
WHY SEPARATE
Separate W_q and W_k make matching asymmetric
If tokens compared raw embeddings, 'similar' would be the only relationship the model could express. Separate projections let "it" seek nouns without being a noun itself — the matrices learn a lookup language where what-I-want and what-I-offer are different subspaces. This asymmetry is most of attention's expressive power.
HEADS
Multi-head = many small QKV sets in parallel
A 4096-dim model with 32 heads runs 32 QKV projections of 128 dims each. One head tracks syntax, another coreference, another positional patterns — then their outputs concatenate and pass through W_o. Cheap parallel specialists beat one expensive generalist. 2026 wrinkle: in practice models use grouped-query attention — Llama-3-8B runs 32 Q heads but only 8 shared K/V heads, shrinking the KV cache 4× (module 12a covers why).
§ 02
The lesson
QKV Matrix Projection Before a token can pay attention to other words, it must split its single dense embedding into three distinct mathematical roles: Query (Q), Key (K), and Value (V). It does this by multiplying its embedding vector against three massive learned weight matrices ($W_Q$, $W_K$, $W_V$).
§ 03
The playground.
Theory above, instrument below. This interactive panel runs live in the page — drag, type, and watch the mechanism respond.