The first attention scored relevance with a small neural network
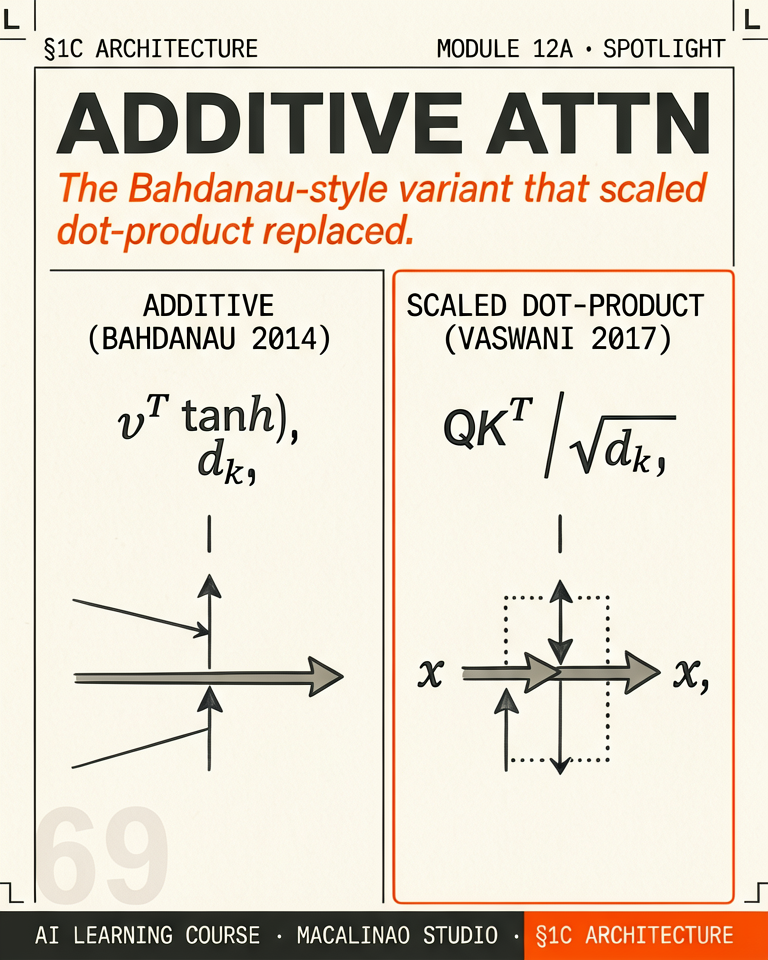
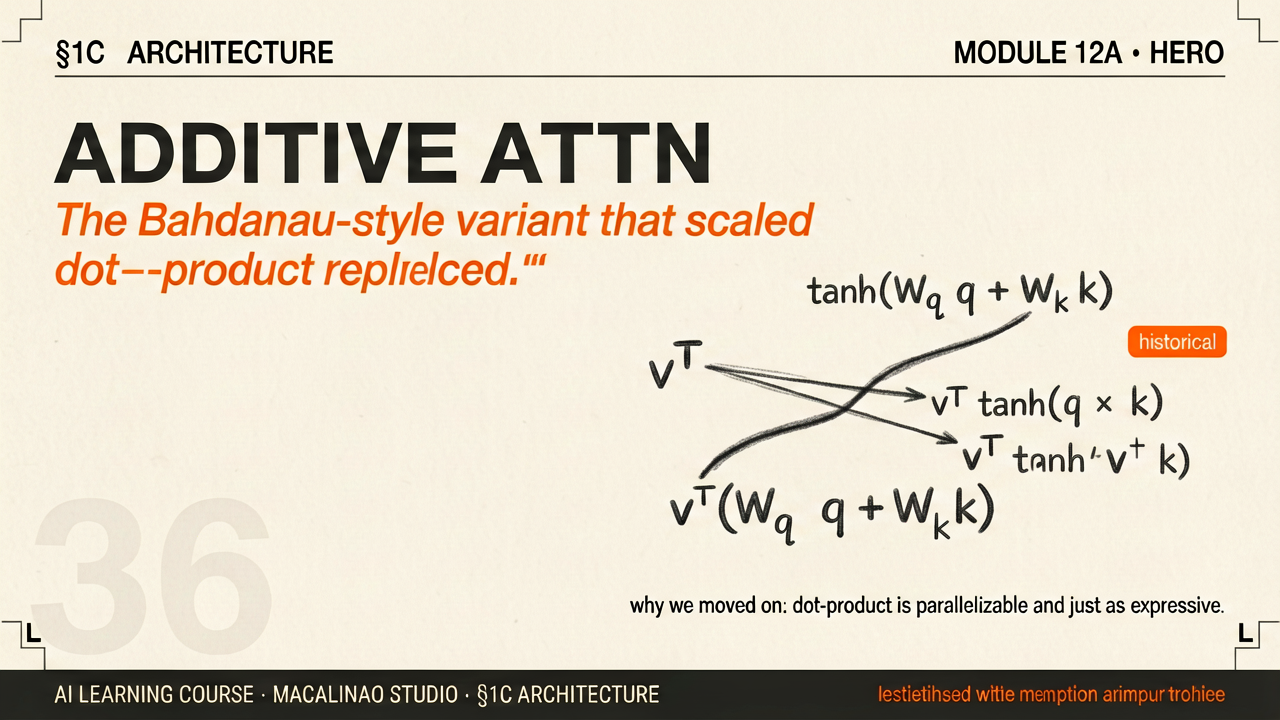
Attention predates the transformer by three years. Bahdanau et al. (2014) bolted it onto an RNN translation model: at each decoding step, a small learned network scored how relevant each input word was to the word being generated —
score = v·tanh(W₁h + W₂s), where h is an encoder state and s is the decoder state. Because the two projections are added inside the tanh, this is called additive attention. It solved the fixed-bottleneck problem of sequence-to-sequence RNNs: instead of cramming a whole sentence into one vector, the decoder could look back at every input position.