The Factory Assembly Line making sure parts fit together perfectly
The "Assembly Line" Analogy
How Data Gets Processed
Think of a Transformer Block like a car manufacturing plant. Your starting word (the "token") is just a raw piece of metal coming in.
The Attention Mechanism is the manager deciding what other words this token should connect with. But it doesn't stop there! The token has to go through the Layer Normalization (LayerNorm) quality control station to make sure the math doesn't explode. Finally, it hits the Feed-Forward Network (FFN), which acts like independent factory workers cementing the facts and logic into the token.
Interactive: The Factory Floor
Click "Send Token" to watch a word get processed through a single Transformer block. Notice the dashed Residual Connections—they act like safety bypass tracks so early information isn't lost if the machines mess up!
Quality Control
Layer Normalization
As the AI calculates millions of numbers, some values can get way too big (like a speaker volume exploding) or incredibly small (fading out).
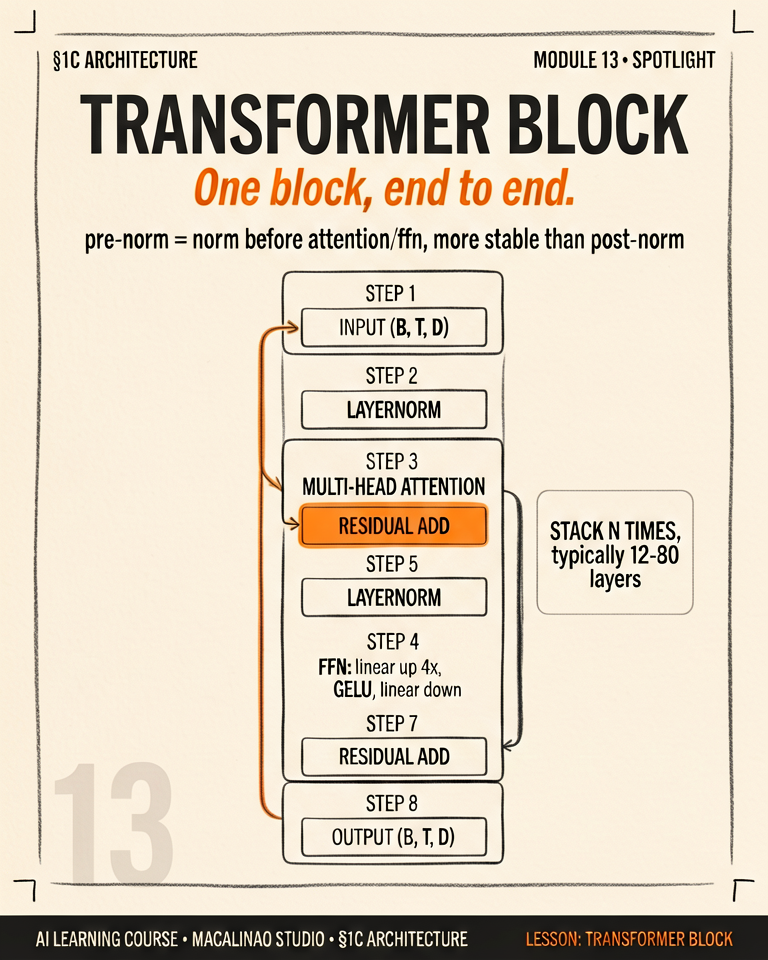
LayerNorm is simply a magical reset button. Every time the data passes through it, it forces the average volume back to a healthy zero, ensuring the network remains stable across 96+ consecutive layers! This depicts Pre-Norm, the modern standard where normalization happens before the sublayer, rather than after.
One more modern refinement: Llama, Mistral, Gemma, and Qwen all use RMSNorm — a simplified LayerNorm that skips the mean-centering step and only rescales by the root-mean-square. Pre-norm + RMSNorm is the 2026 standard recipe.
The Fact Database
Feed-Forward Network
While Attention handles relationships between words, the FFN is essentially the AI's encyclopedic memory. It operates on every word individually.
Modern models use SwiGLU logic gates to process these facts: SwiGLU(x) = (SiLU(x·W_gate) ⊙ x·W_up)·W_down — three weight matrices: a gate branch passed through SiLU, an up-projection it multiplies element-wise, and a down-projection back to model width. This is where the AI stores facts. If the query was "capital of France", the FFN is the part of the brain that fires up and says, "Aha! I know this mathematical pattern maps to 'Paris'."
Where the parameters live
The FFN is roughly two-thirds of the model
The FFN is wide — classically 4× the model dimension, or 8/3× in SwiGLU models (shrunk so the three matrices cost the same as the old two). Either way it holds roughly two-thirds of a transformer's parameters, with attention taking most of the rest. This is exactly the sublayer that mixture-of-experts models swap out: MoE replaces the single FFN with a bank of expert FFNs and routes each token to a few of them (see the MoE card in module 07).
A useful mental model for the whole block: the residual stream is a shared information highway running through the network, and attention and the FFN are stations that each read from it, compute something, and write their result back by addition.
§ 02
The playground.
Theory above, instrument below. This interactive panel runs live in the page — drag, type, and watch the mechanism respond.