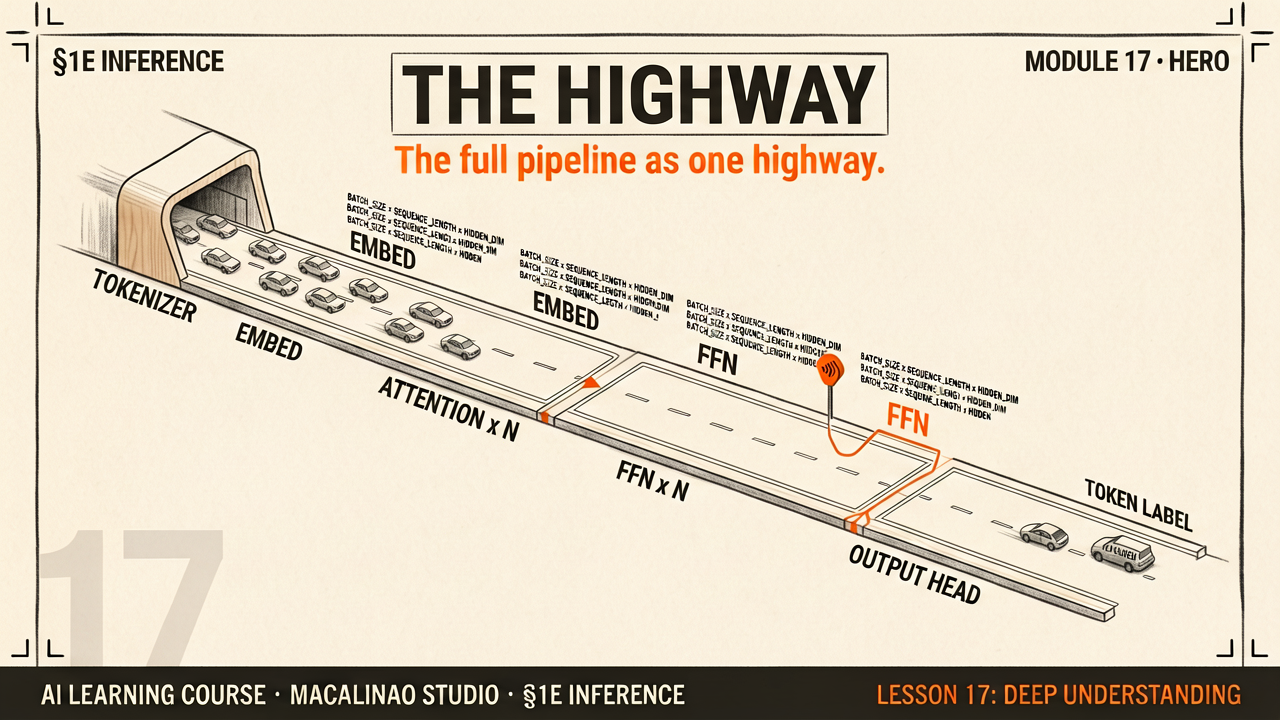
TWO LOOPSTraining loop vs. inference loop
Training: show the model trillions of tokens, compare every predicted next-token against the truth, nudge weights via cross-entropy loss (10, 02). Inference: freeze the weights, feed a prompt, sample one token, append it, repeat (08). Same highway, opposite directions — one writes the map, the other drives it.
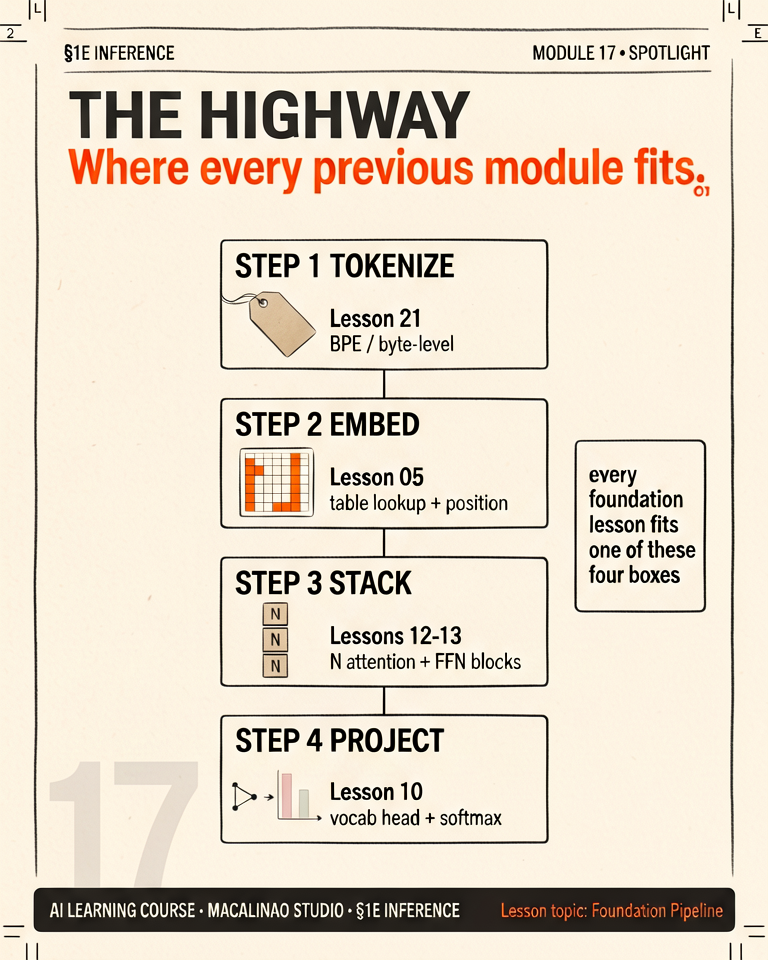
WHERE THINGS PLUG INEvery later topic is a bolt-on to this spine
LoRA (18) swaps small adapter weights into the blocks. RAG (20) edits the prompt before the highway starts. KV caching (08) memoizes the attention math between loop iterations. Vision models (04) just convert patches — instead of words — into the same token stream. If you can place a technique on the highway, you understand it.
2026 ON-RAMPSAgents and thinking tokens extend the same road
Two extensions define 2026. The agent loop (29): the model emits a tool call instead of an answer, the result is appended to the context, and the highway runs again — on-ramps and off-ramps, same road. Thinking tokens (30): reasoning models drive extra laps before taking the exit — generating intermediate tokens the user never sees, trading inference compute for accuracy.