The three components mostly survived — they got upgraded
Stable Diffusion 1.x and 2.x used three separate models: a CLIP text encoder to embed the prompt, a U-Net to denoise in latent space, and a VAE decoder to turn latents into pixels. SDXL added a second text encoder (CLIP ViT-G). The VAE and text encoder did not go away — FLUX and ERNIE-Image keep both. What changed: the U-Net became a diffusion transformer (DiT), the DDPM objective became rectified flow, and the CLIP text encoder became a T5 or a full LLM. Only HiDream-O1 actually drops the VAE and the separate text encoder — the radical pixel-space outlier, not the trend.
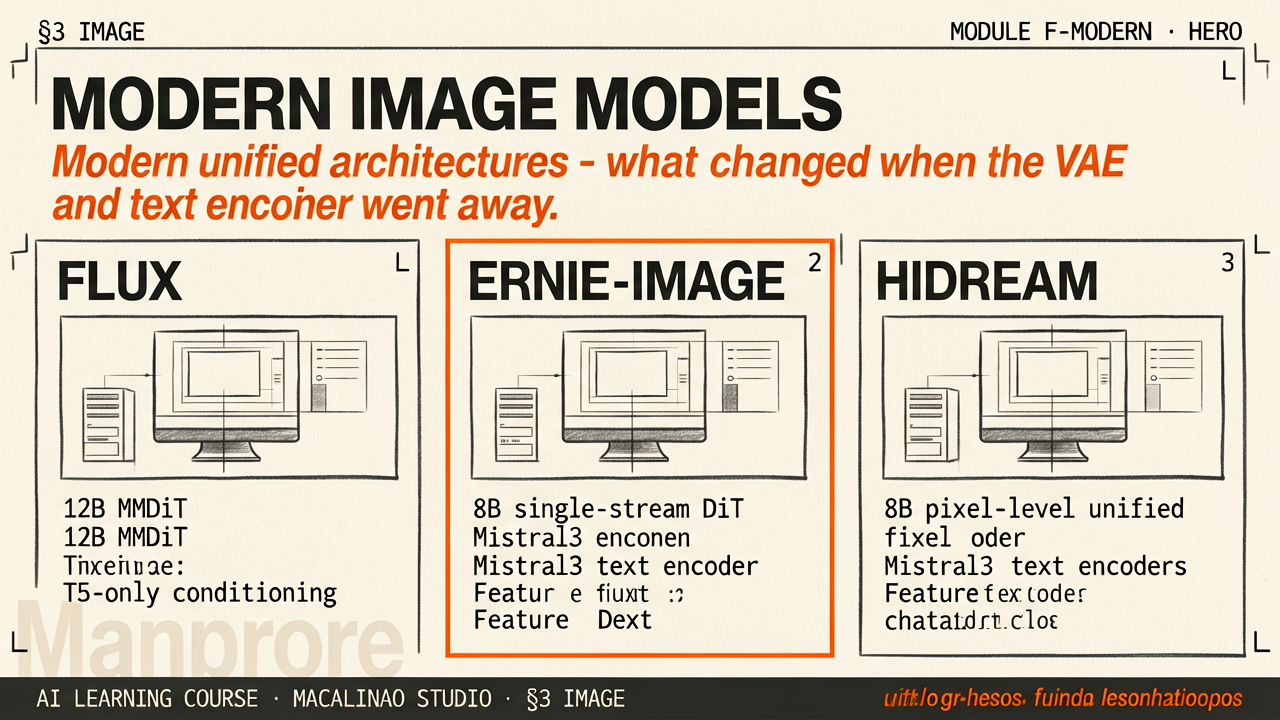
FLUX
MMDiT — double-stream diffusion transformer
Black Forest Labs' FLUX (2024) uses a Multimodal Diffusion Transformer (MMDiT) — the architecture SD3 originated. In its double-stream blocks, text and image tokens keep separate per-stream weights but mix through joint self-attention over the concatenated sequence — there is no cross-attention connecting the streams. FLUX is rectified-flow trained. FLUX.1 pairs the transformer with CLIP + T5 text encoders and a VAE; FLUX.2 (2025) retrains the VAE and swaps in a Mistral-3 VLM as text encoder. Licensing: schnell (4-step distilled) is Apache-2.0, dev is open-weights but non-commercial, pro is API-only.
ERNIE-IMAGE
Single-stream DiT with built-in prompt enhancer
Baidu's ERNIE-Image (2025) is an 8B single-stream diffusion transformer. Open Apache-2.0. Includes a Turbo variant distilled to 8 inference steps via DMD + RL. Ships a Reasoning-Driven Prompt Agent that rewrites a casual prompt into a structured, layout-aware version before passing it to the diffusion model. Strong on long-text rendering (LongText-Bench 0.97+) — the model that finally gets technical labels legible in-image. Note where it sits architecturally: it adopts FLUX.2's VAE and a Ministral-3 text encoder — direct evidence that those components did not go away.
HIDREAM-O1
Pixel-level unified transformer — no VAE, no separate text encoder
HiDream.ai's O1 (2026-05-08) goes the furthest: a single Pixel-level Unified Transformer (UiT) that natively encodes raw pixels, text, and task-specific conditions in one shared token space. No external VAE. No disjoint text encoder. 8B params, MIT license. Native 2048×2048. Supports text-to-image, instruction editing, and multi-reference subject personalization in one model. Ranked #8 on the Artificial Analysis Text-to-Image Arena as of May 2026. Beyond these three: Qwen-Image (20B MMDiT) is the open text-rendering benchmark-setter, and autoregressive/unified-LLM image generation (GPT-Image-class, Gemini-native) is the competing paradigm.